Evals and Testing for Agentic Analytics Systems
How to make an AI analyst dependable with deterministic checks, evaluator judges, and an automated regression suite that runs on schema, context, and model changes.
You’re building an agentic analytics system: users ask questions in natural language, the agent explores context, writes SQL, generates charts, and explains the result. The demo is great. Then production starts and one theme dominates everything else: reliability.
The agent can reason, recover, and ask clarifying questions, but if it can’t do those things consistently, the system doesn’t stick. This post covers how to approach evals and testing for agentic analytics: what to test, how to blend deterministic and non‑deterministic checks, and why you need a regression suite that evolves with your warehouse and instructions.
Reliability in practice
In classic software, failures are loud with exceptions, red tests, and stack traces. In traditional data work, you have dbt tests and warehouse constraints checking not-null, uniqueness, and referential integrity.
Agentic analytics fails quietly. The query runs, a chart appears, and the numbers look reasonable—until someone asks why Q4 beats Q3 when December clearly dipped. The cause is rarely a single bug that a unit test would catch. Instead, it’s usually a chain of small choices that compound over time: a join at the wrong grain, a dbt model rename that nudged the agent toward the wrong table, or an instruction that captured last quarter’s rule but not this quarter’s edge case. Add normal model variance and you end up with a system that feels sharp on Monday and subtly off by Friday.
Evals are how you bring those quiet failures into the open. The goal isn’t to chase a perfect score, but to make reliability visible and maintain it as the system evolves.
What an eval is, and why it helps
An eval is a short, readable contract for how your analyst should behave on a given request. Imagine someone asks for revenue by film. The agent should check for a definition, rely on the warehouse’s own idea of revenue, pick tables that make sense, and present a clear bar chart with a sentence that explains what was grouped and what was summed. You can rerun that same contract whenever schemas, models, or instructions change and quickly see if the expected behavior still holds.
Here’s what that looks like in practice:
question: "Show me revenue by film"
expectations:
tables_used:
- customer
- payment
- film
sql_contains:
- GROUP BY
- SUM(amount)
result_not_empty: true
visualization: bar_chart
judge_criteria:
- "Does the agent's workflow trace show it retrieved relevant definitions, schemas, and context before answering?"
- "Did the agent presented list of films by their revenue in a bar chart in a descending order?"
- "Was the language friendly, proactive, and helpful throughout the interaction?"Deterministic tests
Some parts of the contract are factual and can be checked mechanically without judgment, which is exactly what you want from regression tests that run on every change. The query must use the customer and payment tables, the SQL must parse for your dialect, and the result should not be empty unless the slice is truly empty.
You can be even more specific by asserting the generated code contains required strings:
- Date filters:
WHERE order_date >= '2024-01-01' - Grouping:
GROUP BY film_title - Transformations:
CAST(...)orCOALESCE(...)when your metric definition requires it
These checks are intentionally simple because simplicity is reliable. When a rename or refactor nudges the system, these tests fail fast and tell you exactly what changed, so you can fix the root cause instead of debugging symptoms.
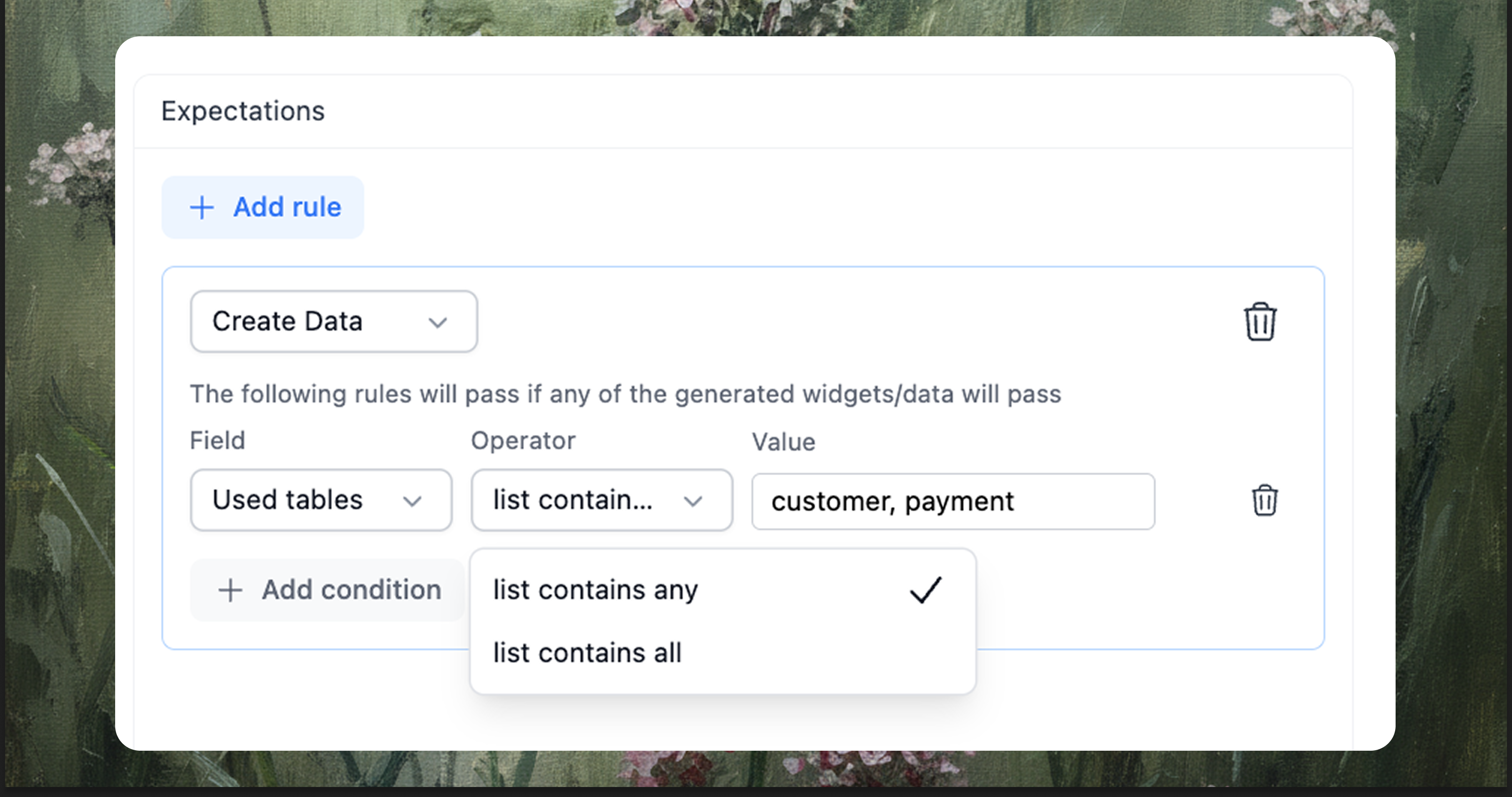
When rules end: evaluators for agentic analytics workflows
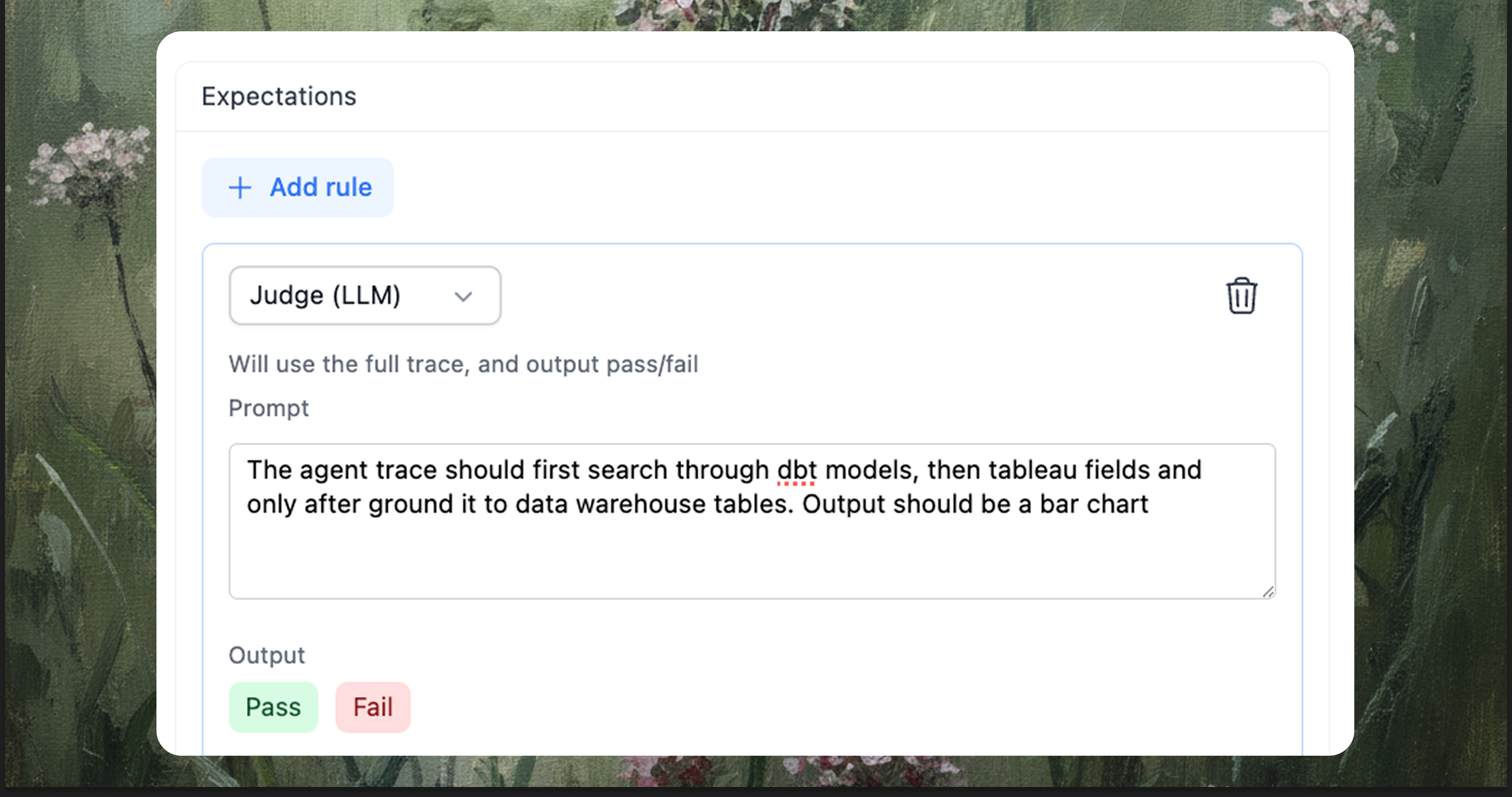
Some expectations are about intent and the path the agent takes to reach an answer, and they rarely fit into a single binary rule even though they matter to anyone reading the result. In these situations a small evaluator reads the full trace and applies a plain rubric, acting like a reviewer of the agent’s choices; with stable settings it is consistent enough to catch the misses people notice first, and it gives you a place to record expectations about workflow, chart choice, and the clarity of what is grouped and what is measured that would otherwise remain unwritten.
- Agentic workflow test: the agent should look up dbt models first, then ground the request with warehouse tables, and only then generate the data and visualization.
- Clarification behavior test: the agent should search available metadata, and if nothing relevant is found, it should follow up with a clear clarification request before attempting to produce numbers.
From one test to an automated, robust testing suite
Start small and honest by picking the 5-10 of questions people ask every week, writing the contracts for those, and letting production teach you the rest as the system encounters new corners of your data. When a failure shows up, resist the temptation to debate whether it should count and instead promote it to a test, because after a month of this habit you will have a suite that mirrors your company’s reality far better than any synthetic benchmark you could design upfront. The next step is to make this suite automatic so it runs when your context changes, not just when manually.
Trigger a full or targeted run whenever any of the following changes are detected:
- data structure change, such as a new table or a new column
- dbt changes, including model refactors and metric updates
- instructions change, whether scoped rules or domain guidance
- system prompt change that affects global agent behavior
- tool use change, like enabling a new retrieval step or a different executor
- LLM change, including provider switch or temperature shift
Here’s a concrete example: your instructions defined “active users” as users who spent more than $5 USD in the past 14 days. Someone updates that definition to “users who spent more than $10 USD in the past 30 days.” The eval suite runs automatically and catches that three tests now fail because the agent is filtering incorrectly and counting twice as many active users as expected. The suite blocks the merge until you verify whether the tests or the instruction needs adjustment.
When a change lands, track it and run the suite automatically. Only merge to the main agent after the suite succeeds, and produce a verbose report that shows how the agent performed, which contracts passed, which failed, and which were skipped with reasons. This turns reliability from a once in a while task into part of your normal development loop.
Closing thoughts
Agentic analytics will replace many dashboard flows because it can explore, reason, and explain, but the path from demo to dependable runs through testing. You need to blend deterministic checks that lock in the foundations with judge-based evaluations that encode human intent. Your context will evolve—tables change, dbt models get refactored, instructions get updated—so treat your evals as a regression suite that evolves alongside it.
The practical approach is to start with the five or ten questions your team asks every week, write the contracts for those, and run them on every schema change. After a month you’ll have a suite that mirrors your company’s reality better than any synthetic benchmark you could design upfront, and you’ll catch the quiet failures before your stakeholders do.
The goal isn’t a perfect score. It’s building a system your stakeholders trust because it behaves consistently, even as everything around it changes.