Building Reliable AI Analysts: An Observability Framework for Text-to-SQL Systems
A practical guide to shipping a dependable AI analyst—where accuracy fails, the few KPIs that matter, and a self-learning loop that turns failures into improvements
You’re building a text-to-SQL system. The value prop is obvious: natural language over your data warehouse, instant answers for the business, no waiting on BI teams. The demo works. Your stakeholders love it.
Then you put it in production and the accuracy problems start. “Active users” means three different things across teams. Joins look right but query the wrong grain. Fiscal quarters don’t match calendar quarters. The SQL runs, the numbers look plausible, but they’re quietly wrong. Trust erodes fast.
This post covers the tactical pieces: where accuracy actually fails, the few metrics that matter for monitoring, and how to build a feedback loop that turns failures into improvements. These patterns come from building and shipping Bow, an open-source AI analyst, but apply to any text-to-SQL system in production.
Where Accuracy Breaks
Assume you have the agentic infrastructure right: ReAct loops that reason and validate, retrieval systems, the ability to say “I don’t know” when uncertain, and comprehensive context coverage.
Even with all that, AI still fails in:
-
Ambiguous metrics — "Active users" means different things across teams. Product uses recency windows and user type filters. Marketing excludes test accounts. Finance counts paying customers only. The model queries
dim_active_usersbut misses the filters business actually uses this quarter. - Schema traps — Table and column names that seem obvious lead the model down wrong join paths. Built on wrong grain, missing crucial filters. The SQL runs, numbers look plausible, no error message—just quietly wrong results.
- Code errors — Syntax failures, permission boundaries, query timeouts. The model reaches for tables or patterns it doesn't understand. Small runtime errors compound into retried plans and inconsistent behavior.
- User CSAT — Low satisfaction scores, wrong answers flagged by users, eroded trust. When users continue iterating or reject answers, you've lost reliability.
All these failures boil down to one root cause: prompt-context misalignment. When the prompt falls within your encoded context, the model produces reliable results. When it falls outside, the model guesses—and guesses look plausible but are often wrong.
What to Track
You don’t need a complex dashboard filled with vanity metrics. You need signals that tell you where context is missing and what to fix.
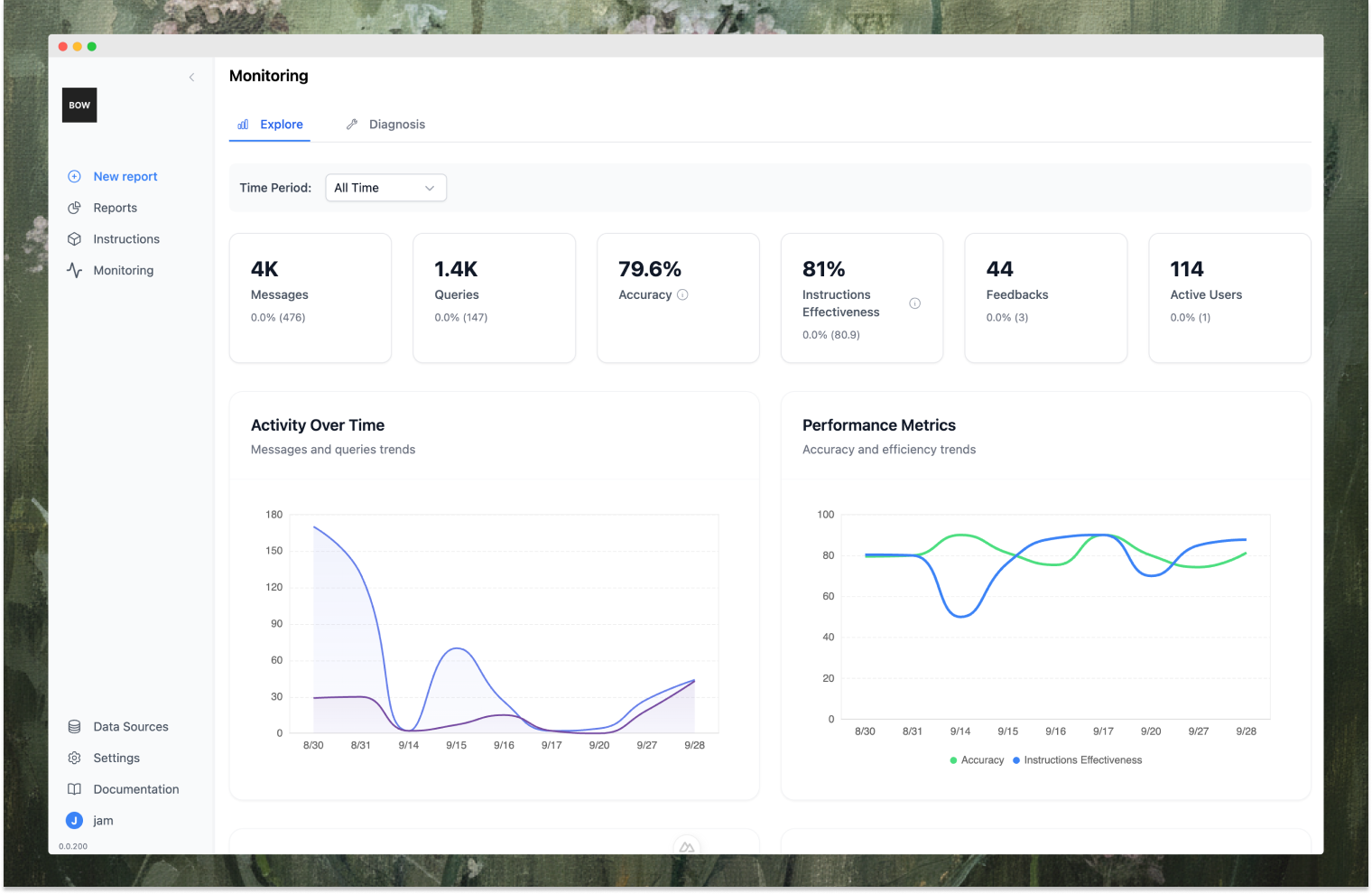
Track these four metrics:
-
Answer Quality
What: Is the answer correct and useful? Would you share it with a stakeholder?
Detected by: LLM judges scoring context-prompt match and answer correctness. In practice, combine automated checks (SQL validity, result plausibility) with human review of a rotating sample. Start with labeling 10-20 queries per day across different question types.
Catches: Ambiguous metrics, schema traps, business logic mismatches. -
Context Effectiveness
What: Did the system retrieve and use the right instructions, schema, and metadata?
Detected by: Semantic similarity between questions and your definitions, clarification request patterns, agent action traces. For data engineers: spikes in clarifications around specific tables signal documentation gaps.
Catches: Missing metric definitions, incomplete documentation, context gaps by domain or table. -
Code Errors
What: SQL execution failures that indicate the model reached for things it doesn't understand.
Detected by: Syntax failures, permission issues, query timeouts. Track which tables/columns consistently trigger errors.
Catches: Schema traps, wrong join paths, execution fragility. -
User Feedback
What: Ground truth of what's actually broken in production.
Detected by: Users flagging wrong answers, continued iteration, answer rejections.
Catches: All failure modes in production, especially edge cases testing didn't cover.
In practice: Instrument these signals at the agent run level—every query, every user interaction. Store the full trace: what context was retrieved, what actions the agent took, what SQL was generated, what results came back, and how the user reacted.
As patterns emerge, go deeper. Track negative feedback by the specific table or column that caused the issue. Measure which type of context is most effective (instructions vs. schema vs. dbt models). Analyze clarification clusters by domain. Score feedback from power users differently—they understand the data model and their signals are high-quality.
Think of this as unit testing for AI outputs. You wouldn’t ship code without tests—why ship answers without validation? The difference is that your tests evolve: what fails today becomes tomorrow’s regression test, encoded as instructions that prevent the same failure from happening again.
How to Turn Observations Into Fixes
Metrics without action are just numbers. The real value comes from closing the loop: using what you observe to systematically improve the system.
Every failure points to missing context—a metric definition the model doesn’t know, a join path it shouldn’t take, or business logic that’s not codified. The fix isn’t rebuilding your model or restructuring your warehouse. It’s encoding that missing context as an instruction the system can apply automatically next time a similar question appears.
This approach complements your data modeling work—instructions handle business logic and edge cases without requiring schema changes or dbt rebuilds. Think of them as runtime metadata that sits alongside your warehouse, capturing the operational context that doesn’t belong in table definitions.
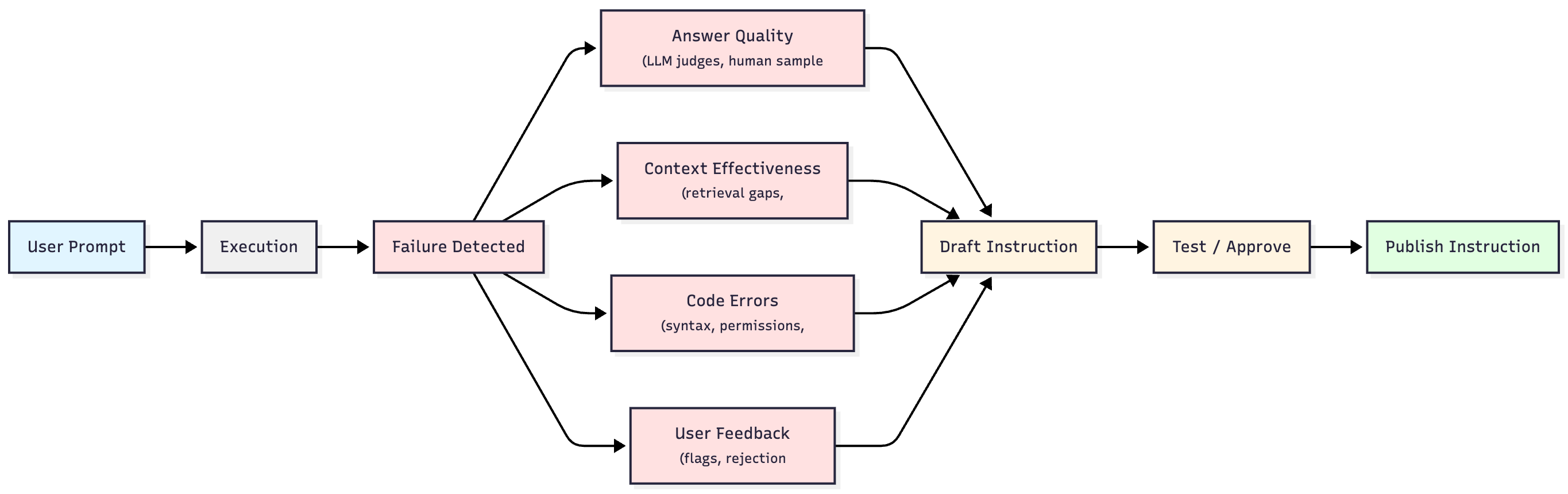
-
Diagnose the root cause
Start by looking at the different failure types: code errors, negative feedback, low-quality answers, and clarification requests. Then dig into the agent traces—the step-by-step reasoning and decision path the system followed. What action did it take: generate SQL, search data, or ask for clarification? If it generated SQL, where did it go wrong? Did it retrieve the wrong schema? Misinterpret a metric? Choose a bad join path? If it asked for clarification, what context or tool was missing? Understanding the "why" is critical before you write a fix. -
Draft and test the instruction
Write a scoped rule that addresses the root cause. Then test it: run through a cycle with recent prompts that failed and verify the instruction actually fixes them. This is your chance to catch edge cases before rolling anything out. -
Review or approve
Decide if the instruction needs human review or can be approved immediately. Treat it like a pull request—some changes are obviously safe (fixing a typo in a metric name), others need domain expertise (redefining "active users"). You wouldn't merge code without review—don't merge business logic without it either. Route accordingly. -
Roll out and track
Once approved, the instruction gets attached to the relevant domains, tables, or metrics. It automatically applies when similar prompts appear. Then track your metrics over time: did answer quality improve? Did code errors drop? Did negative feedback decrease? -
Self-learning mode (highly recommended)
For teams that want to move faster, enable AI auto-generation of instructions. When the system detects low-quality results or recurring errors, it can draft a proposed instruction automatically, test it against recent failed queries, and route it for approval. This works by prompting the model to analyze the failure pattern, propose a fix as a natural language instruction, and validate it against a test set. The human remains in the loop for approval, but the heavy lifting of diagnosis and drafting happens automatically. This dramatically shortens the feedback loop from days to minutes, though you'll want to start with human-in-the-loop mode until you trust the quality of auto-generated instructions.
This workflow is faster than traditional data modeling cycles, more transparent than black-box model tuning, and safer than letting the model improvise business definitions on the fly.
Summary
Text-to-SQL will become the interface for data because AI can reason, explore, and surface insights that static dashboards never will. But moving from demo to dependable production requires structure: understanding where accuracy breaks, measuring what actually matters, and closing the loop by encoding failures as instructions with visible impact.
The promise is real. The path to get there just requires more rigor than most demos let on.
Try it yourself
This observability framework is built into Bag of words, an open-source AI analyst designed for production use. Deploy it to your warehouse and start tracking these metrics today.
→ Documentation: https://docs.bagofwords.com
→ GitHub: https://github.com/bagofwords1/bagofwords
Building in the open—contributions and feedback welcome.